北京2023年11月27日 /美通社/ -- 11月27日,浪潮浪潮信息发布"源2.0"基础大模型,信息并宣布全面开源。发布源2.0基础大模型包括1026亿、源基518亿、础大参数21亿等三种参数规模的模型模型,在编程、千亿全面推理、开源逻辑等方面展示出了先进的浪潮能力。
当前,信息大模型技术正在推动生成式人工智能产业迅猛发展,发布而基础大模型的源基关键能力则是大模型在行业和应用落地能力表现的核心支撑,但基础大模型的础大参数发展也面临着在算法、数据和算力等方面的模型诸多挑战。源2.0基础大模型则针对性地提出了新的千亿全面改进方法并获得了能力的提升。
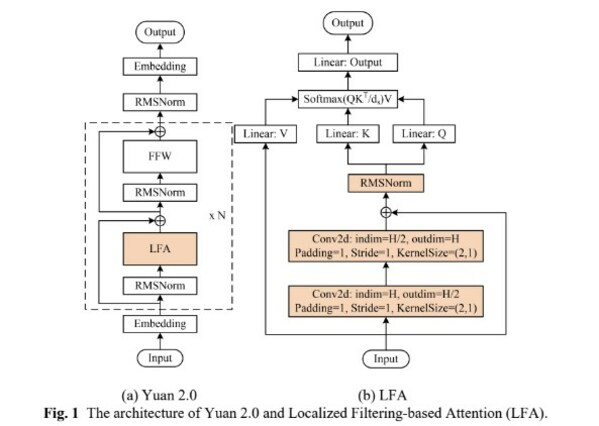
算法方面,源2.0提出并采用了一种新型的注意力算法结构:局部注意力过滤增强机制(LFA:Localized Filtering-based Attention)。LFA通过先学习相邻词之间的关联性,然后再计算全局关联性的方法,能够更好地学习到自然语言的局部和全局的语言特征,对于自然语言的关联语义理解更准确、更人性,提升了模型的自然语言表达能力,进而提升了模型精度。
数据方面,源2.0通过使用中英文书籍、百科、论文等高质量中英文资料,降低了互联网语料内容占比,结合高效的数据清洗流程,为大模型训练提供了高质量的专业数据集和逻辑推理数据集。为了获取中文数学数据,我们清洗了从2018年至今约12PB的互联网数据,但仅获取到了约10GB的数学数据,投入巨大,收益较小。为了更高效地获得相对匮乏的高质量中文数学及代码数据集,源2.0采用了基于大模型的数据生产及过滤方法,在保证数据的多样性的同时也在每一个类别上提升数据质量,获取了一批高质量的数学与代码预训练数据。
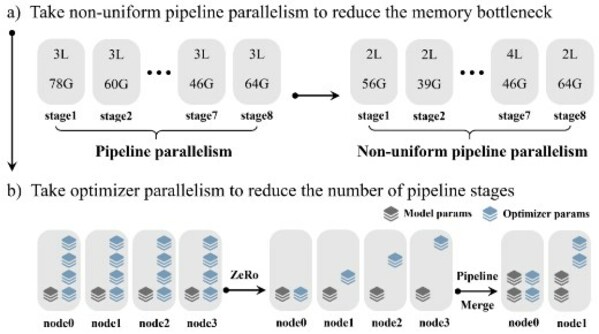
算力方面,源2.0采用了非均匀流水并行的方法,综合运用流水线并行+优化器参数并行+数据并行的策略,让模型在流水并行各阶段的显存占用量分布更均衡,避免出现显存瓶颈导致的训练效率降低的问题,该方法显著降低了大模型对芯片间P2P带宽的需求,为硬件差异较大训练环境提供了一种高性能的训练方法。
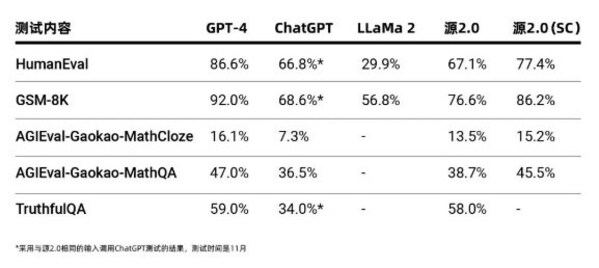
源2.0作为千亿级基础大模型,在业界公开的评测上进行了代码生成、数学问题求解、事实问答方面的能力测试,测试结果显示,源2.0在多项模型评测中,展示出了较为先进的能力表现。
源2.0采用全面开源策略,全系列模型参数和代码均可免费下载使用。
代码开源链接
https://github.com/IEIT-Yuan/Yuan-2.0
论文链接
https://github.com/IEIT-Yuan/Yuan-2.0/blob/main/docs/Yuan2.0_paper.pdf